12 1️⃣『』 One Proportion Z-Interval for \(\hat{p}\)
Suppose you want to know the true proportion of Freshmen at TJ who’ve had Boba tea. You select a SRS of 30 students and ask them if they have had Boba tea. You find out that, among your sample, 65% have had Boba tea.
Up to now, the promise in this class that that we’ll give you the tools to estimate the true population parameter using only a sample. So now we return to this question: how close were you to the true percentage of TJ Freshmen who’ve ever had Boba tea?

Here’s what we know:
- We know that our sample was not biased, because it was an SRS.
- We know that this one sample is part of a sampling distribution, that is approximately normal.
- We know that if we took another sample, our mean sample statistic will be different, because of sampling variability.
- Sampling variability fundamentally means that we know we can sort of trust our sample, but we can’t completely trust it– because we know for a fact that our sample statistic is not exactly equal to the true population parameter.
On top of that, we still don’t know how close we are to the sample, because we don’t know the population standard deviation. It is completely possible that we got very unlucky, and our sample is completely unrepresentative of the population. The chances that we get an unrepresentative sample with SRS is smaller, but it is not 0.
If you were to guess the number of jelly beans in a jar, you’re more likely to be correct by giving a range of values, rather than a single number. We are more likely to capture the “true” population parameter with a range of values instead of a single estimate. This range of values is called a confidence interval.

12.1 Interpreting Confidence Intervals
Every confidence interval is constructed by using the point estimate. The point estimate is the sample statistic that you calculated initially.
From there, we create an upper and lower bound by adding and subtracting a margin of error from the point estimate. In other words:
\[ \text{Confidence Interval}= \text{Point Estimate} \pm \text{Margin of Error}\]
The margin of error, is based on standard deviation of the sampling distribution (as referenced in 11.5.1 and 11.4) and the critical value derived from the Confidence Level. In other words, \(\text{Margin of Error}= \text{critical value} * \text{standard deviation of sampling distribution}\) (You do not need to know the Margin of Error calculation yet, as we will revisit this later.)
Graphically speaking, a confidence interval looks like this:
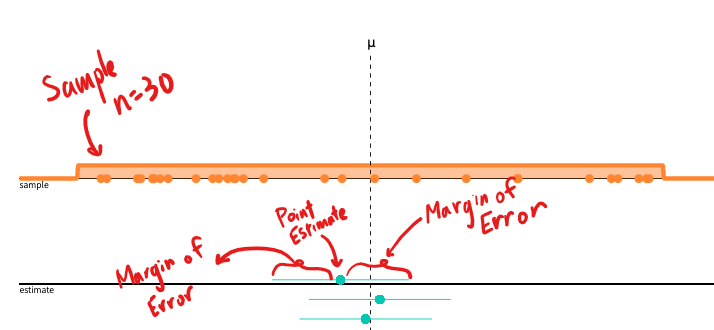
FIGURE 12.1: Confidence Interval, Annotated
12.2 Interpreting Confidence Levels
Your final grade in this class will be between an F and an A.
This range guarantees that I am always right about what your final grade in this class is. But it’s also useless.
On the other hand, “your final grade in this class will be between 92.3% and a 92.4%” is incredibly narrow and gives you a lot of info, but also increases the chance that I will be wrong. When we pick a range of values, we need to ensure that it lies in a good middle ground between being too narrow that we don’t capture the value, but not too wide that the confidence interval becomes useless.
A Confidence Level determines how “wide” will be in order to properly capture the true population parameter. It is usually 95%, or 99%. The critical value is the associated z-score with the middle % of the sampling distribution.
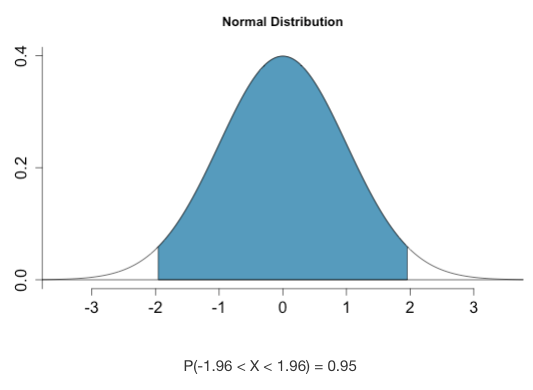
FIGURE 12.2: The middle 95% of the Normal distribution is associated with the z-scores 1.96 and -1.96.
If you repeatedly took samples from the population of size \(n\), you can expect that 95% of the confidence intervals that you construct will capture the population parameter.

FIGURE 12.3: Repeatedly creating multiple confidence intervals over and over. THis is a recording from https://seeing-theory.brown.edu/frequentist-inference/index.html#section2
Notice that, sometimes, we still get an unlucky sample that, even with the wider width, fails to correct capture the true population parameter. That confidence interval is highlighted in red.
A confidence level of \(95%\) does NOT mean that the single confidence interval you create has a 95% probability of capturing the true population parameter.
Your confidence interval either captures the true population parameter, or it doesn’t capture it. That probability is either 0% or 100%.
A 95% confidence interval states that, over repeated sampling, around 95% of the confidence intervals you construct will capture the true population parameter.
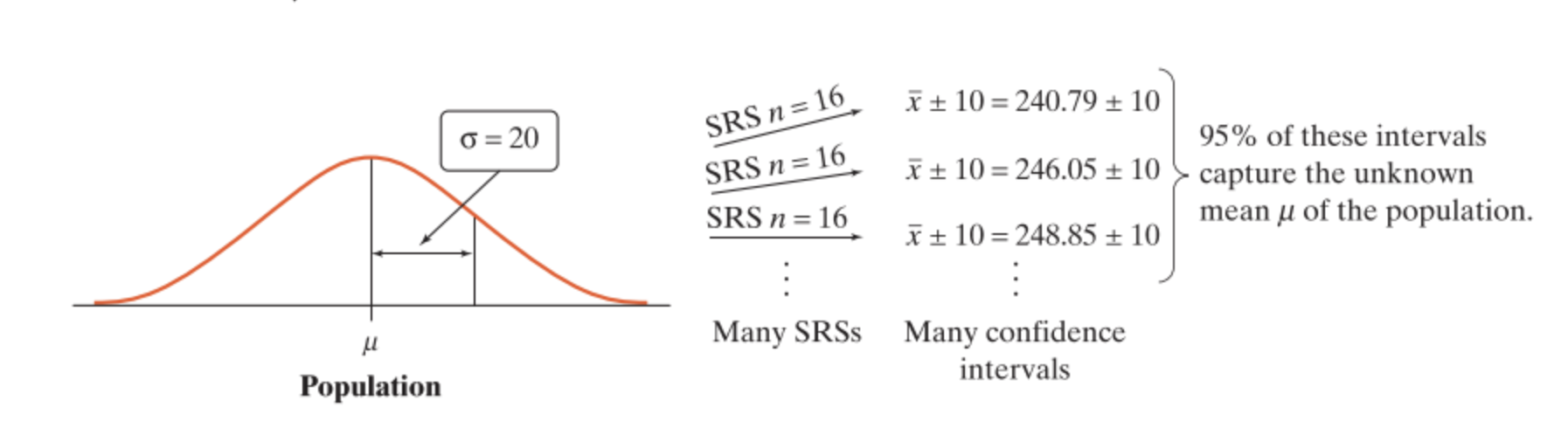
FIGURE 12.4: To say that \(\bar{x} \pm 10\) is a 95% confidence interval for the population mean \(\mu\) is to say that, in repeated samples, 95% of these intervals will capture \(\mu\).
If you lower the confidence level, the width of the confidence intervals decreases, and you get more red confidence intervals.
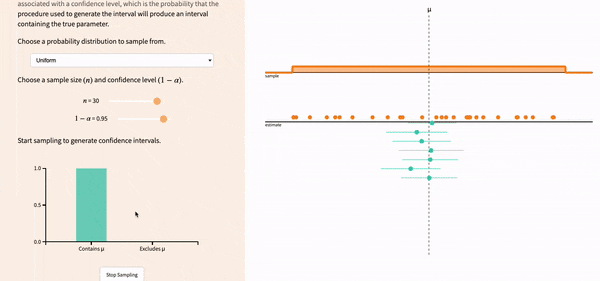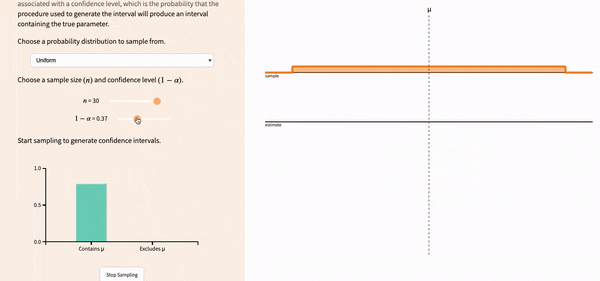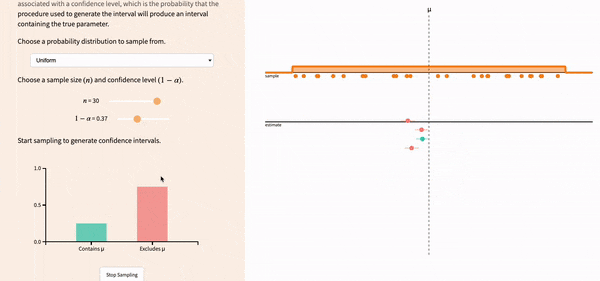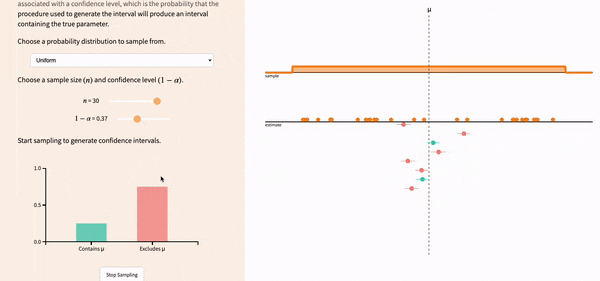
FIGURE 12.5: Lowering the confidence level leads to more precise intervals, but increases the likelihood of not correctlly capturing the population parameter.
12.3 Confidence Intervals of One Proportion
Example:Sleep Awareness Week begins in the spring with the release of the National Sleep Foundation’s annual poll of U.S. sleep habits and ends with the beginning of daylight savings time, when most people lose an hour of sleep. In the foundation’s simple random sample of 1029 U.S. adults, 48% reported that they “often or always” got enough sleep during the last 7 nights.
Construct a 98% confidence interval for the proportion of adults that “often or always” got enough sleep during the last 7 nights.
In every method of statistical inference (where we try to draw conclusions about a population based on a sample), we follow the four step process of State, Plan, Do, Conclude.
12.3.1 State
Use this sentence stem:
We want to construct a One-Proportion Z-Interval for the proportion of adults who “often or always” get enough sleep during the last 7 nights, with 98% confidence.
Then, list out statistics that are important to the problem:
n=1029
$= 0.48
12.3.2 Plan: Check for Conditions
Before we figure out what the appropriate Critical Value is associated with a 98% confidence level, we need to ensure that the sampling distribution follows the normal distribution. There are three conditions you need to check for:
Random: The sample must be a random sample. This diminishes sampling bias.
Normal: \(np \ge 10\) and \(n(1-p) \ge 10\). This generally helps us fulfill the central limit theorem, so the sampling distribution of \(\hat{p}\) is approximately Normal. Both these numbers should be integers, since they represent counts in the sample. If you get something that is very close to an integer, attribute it to rounding error.
Independent (10% Condition): The number of successes (observational units in \(\hat{p}\)) and the number of failures (observation units not in \(\hat{p}\)) must be less than 10% of the population. This is necessary because if your sample size is too large, then that increases the lik elihood that the same observational units will be selected for multiple samples. That increases the chances that the samples will have response bias.
Let’s see how this works in our example:
Random: The sample of 1029 US adults was randomly selected. ✅
Normal: To use a Normal approximation for the sampling distribution of \(\hat{p}\), we need both \(np\) and \(n(1-p)\). Since we don’t know \(p\), we use \(\hat{p}\) instead. ✅
We check that \(np = 1029(0.48)= 494 \ge 10\) and \(n(1-p) = 1029(1-0.48) =535 \ge 10\). Since both are greater than 10, we meet this condition.
Independent: If our is sample size \(n=1029\) is exactly 10% of the population, then that means the smallest possible population size is \(10*1029=10290\). Given that we know that there are way more than 10,290 adults in the U.S., it is reasonable to assume that our sample size is less than 10% of the population. ✅
Since we pass all three conditions, we can continue.
12.3.3 Do
Let’s start off with talking about how to the confidence interval manually.
First, we need to calculate the critical value \(z^*\) . If our confidence level is the middle 98% of the normal distribution, that means 2% is outside the middle 98%. Thus, there is 1% remaining on either side of the tail.
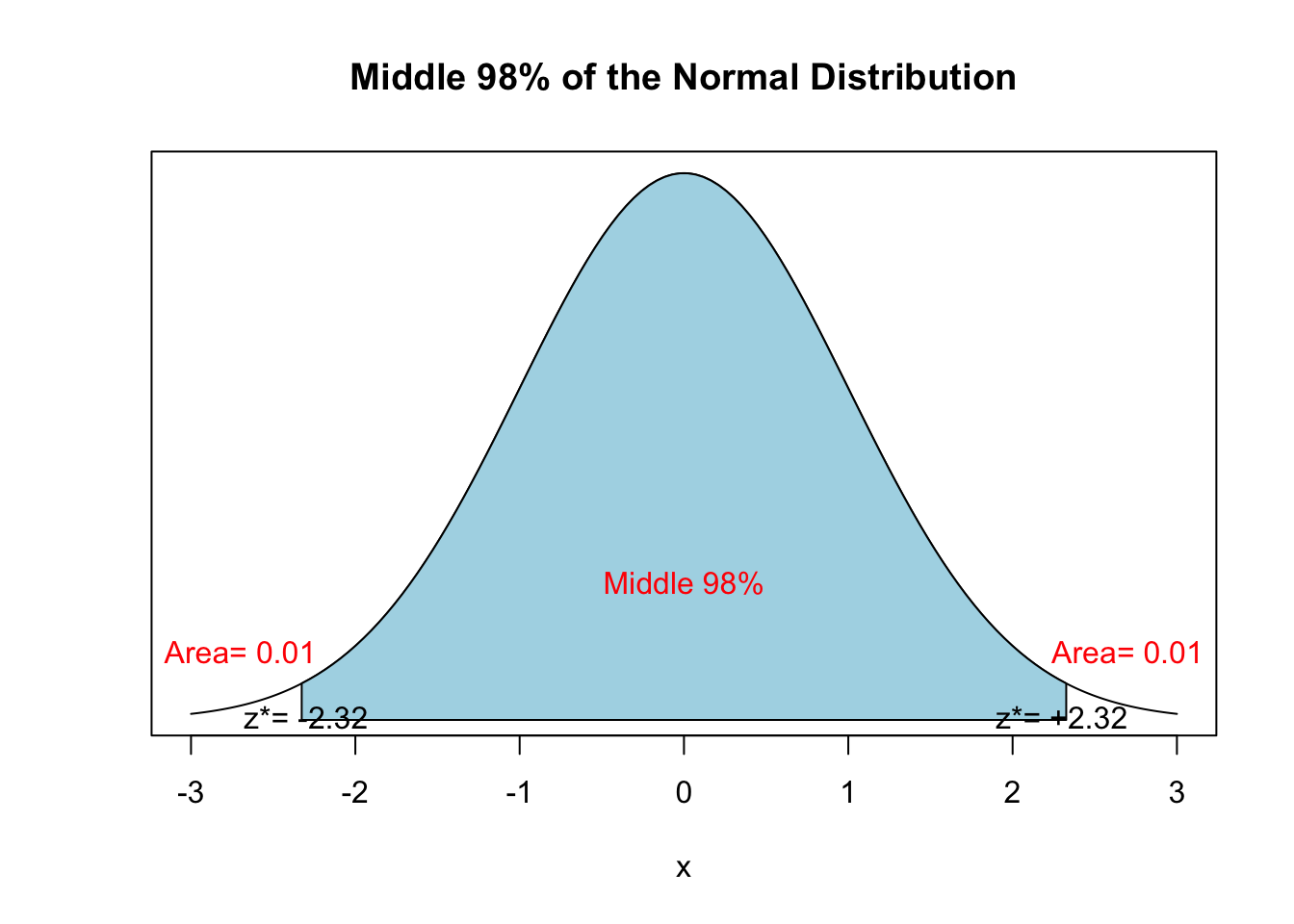
To do this, use the qnorm() function.
qnorm(0.01)## [1] -2.326
qnorm(0.99)## [1] 2.326Notice that they are both the same magnitude, so we only take the positive value.
Next, calculate the margin of error. For a One-Sample Z-Interval, the formula is:
\[ \text{Margin of Error}= z^* \sqrt{\frac{p(1-p)}{n}}\]
Plugging in the numbers from our example, we have:
Mathematically:
\[ \text{Margin of Error}= \\ 2.326 * \sqrt{\frac{0.48(1-0.58)}{1029}} \\= 0.036231 \]
Finally, we can create a 98% confidence interval.
#Lower Bound
0.48- moe## [1] 0.4438
#Upper Bound
0.48+ moe## [1] 0.5162\[ \text{98% CI}= \hat{p} \pm \text{M.o.E}= 0.48 \pm 0.036231 = [0.4437683, 0.5162317]\]
12.3.4 Conclude
Now we want to interpret the confidence interval in context. Use this sentence starter:
We are _____% Confident that the interval from _______ to _____ captures the true ________.
In our example, it’s:
We are 98% Confident that the interval from 0.44377 to 0.51623 captures the true proportion of U.S. adults who “often or always” get enough sleep in the past 7 nights.
You must always use context. Failure to do so would mean lost points.
12.4 In R
Finally, there is a built-in way to do this in R, using the prop.test() command. Instead of inputting the actual \(\hat{p}\), however, you input the count of “successes” within the context of the problem. If 48% of U.S. Adults report that they “often or always” get enough sleep, then \(0.48*1029=493.92\), which we round up to \(494\) and attribute the decimal to rounding error.
prop.test(x= 494,
n=1029,
conf.level = 0.98,
correct=FALSE)
Regardless of whether you calculate the interval by hand or through R, or the TI-84, you must complete the State, Plan, and Conclude portions as shown. Failure to do so results in lost points.